路由解读那点事儿
这篇文也是靠很多来源,各路大哥们提供的资料与我司路由大神的讲解才有的。再次感谢这些朋友们。
目标
本文的目标是讲解一下路由追踪的信息,名词解释,以及以下内容:
- Traceroute 是什么
- 如何解读路由器 DNS 名称
- 了解延迟信息
- 非对称路由
- 多重路由
- MPLS 与 Traceroute 的关系
Traceroute 到底是什么?
Traceroute 是一个用来获取当前网络沿途路径的路由信息的工具。虽然这东西很简单,但是网络排障中依旧有很重要的用途。
我们知道网络上数据是以数据包的形式传输的,在每一个数据包中都有个标头告诉所有处理这个数据包的路由器,要怎么传输。在众多标头的信息中,TTL(Time to Live) 是一个很特别的包头,会描述这个数据包到底要经过多少个路由器还没传输到终点就被丢弃。
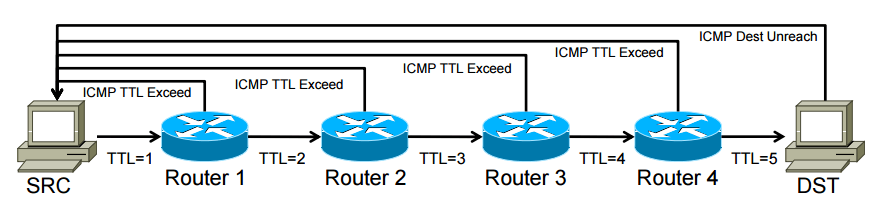
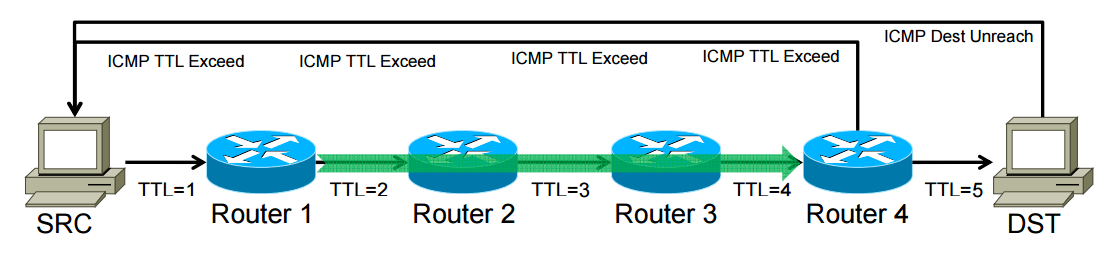
在 Traceroute 里,程序首先会将一个数据包送去指定地址,并将包头 TTL 设置为 1,这样,当包抵达第一个路由器时就会被丢弃,同时这个路由器会发出 ICMP 的 TTL Exceeded 响应包到我们这边作为响应,同时附上路由器的 IP 地址。重复以上步骤并不断的增加 TTL 数值,直到包抵达目标地址时,目标设备会返回一个 ICMP Destination Unreachabel 的包,告诉你包已经抵达目的地。
下面的图大致讲解了这个过程:
多讲一些的话:
- 每一次 traceroute 通常都会传输多于一个的包
- 大部分情况下都会在每一次增加 TTL 时传输三次测试数据包(每一次增加的 TTL 的结果称为一个节点)
- 会在每一个节点出现同等数量的延迟数据,或是如果节点不响应也会出现
- 并不是所有的 traceroute 程序都使用同一种类型的测试数据包
- *nix 通常使用 UDP,Windows 是 ICMP,也有使用 TCP 的工具
Traceroute 的延迟是如何计算的
- 记录传输时的时间
- 记录接收时的时间
- 两者相减
在传输过程中,路由器并不会对数据包做时间计算,只是很简单的把 ICMP 信息直接传回去。值得注意的是,traceroute 记录的延迟值是数据包来回的延迟值,虽然 traceroute 只会显示你去目的地的路由,不弱如果数据包传回来的路径不同的话(往返不同路),测到的延迟值就都会受到影响。
贴一个路由层级的图解:
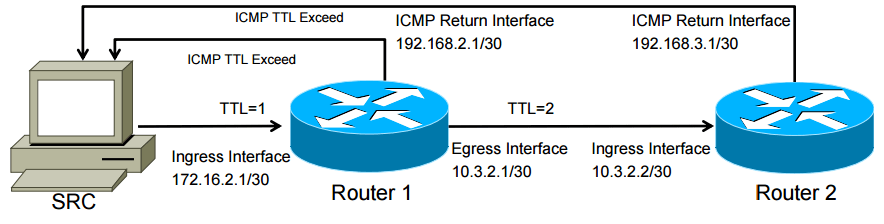
从上面的例子中我们看到 TTL=1 的包从连上网卡后进入路由器,由于 TTL 在路由器内会逐减,所以包的 TTL=0。根据规范,路由必须向来源发一个 ICMP TTL Exceeded 信息,这时我们就知道路由器这个网卡的地址了。于是,tracetoure 的输出就会是 172.16.2.1 10.3.2.2
如何解读路由器 DNS(PTR) 信息
这部分算是很重要的部分了。要看懂 traceroute,这个技巧是最有用也是最重要的。通过解读路由器 PTR 记录,我们可以从名字中获得很多有用的信息,例如:
- 路由器的地理位置
- 路由器的接口类型和速度
- 路由器的类型和作用
- 边界路由和不同网络之间的关系
通常要理解网络出现的问题,知道路由器的地理位置是很重要的。知道了地理位置之后,我们可以辨认出不正确或者非最佳的路由、可以理解网络的互联关系、找出问题所在(例如找出高延迟的路由节点)。通常来说,路由器的地理位置通常会以以下的代码去表示:
- IATA 机场代码
- CLLI 代码
- 城市简称
- 靠猜(😒
IATA 机场代码
IATA 机场代码由于是国际通用的,所以通用范围非常广,且 IATA 代码也通常会用于一些大型的网络交汇点,例如:
- 洛杉矶 = LAX
- 硅谷 = SJC
- 东京 = NRT
- 香港 = HKG
- 台北 = TPE
有时候,我们并不会用正规的机场代码去标识路由器的地点,尤其是该城市有多个机场的时候适用,又或者是正规机场代码根本就不是一看就会的时候。例如纽约有三个机场:JFK、LGA 和 EWR。你可以一眼就看出这些地方么?所以纽约的路由通常会以 NYC 去表示位置。又例如弗吉尼亚州南部的机场代码是 IAH,华盛顿则为 DCA,不过我们通常称为 WDC。
CLLI 代码
CLLI 代码全称 Common Language Location Identifier 这东西有点历史了,在很久以前由 Telecordia 公司编制与发售,是电话公司经常采用的一套城市代码,例子有 HSTNTXMOCG0 和 DLLSTXRNDS1。不过现在 ISP 也不只是电话公司,所以通常也只会采用 CLLI 的首六个字母。例子有:
- 休斯顿 = HSTNTX
- 达拉斯 = DLLSTX
这种代码在北美确实是一种标准,而且在一些有较多网络节点的大型网络上也比较常见。不过一旦离开北美洲,这套代码可能就不太适用了。有些 ISP 还会为了保持格式一致,会为其他不在北美洲的城市创作这一套代码(NTT 就是这样的),例如荷兰的阿姆斯特丹会变成 AMSTNL,又或是东京会变为 TOKYJP。
瞎鸡儿改
有时候 ISP 的一些工作人员在搞事的时候就会索性为自己的节点瞎鸡儿改名,举几个例子(下面简称 XJBG):
- Chicago 芝加哥
- IATA: ORD, MDW
- CLLI: CHCGIL
- XJBG: CHI
- Toronto 多伦多
- IATA: YYZ, YTC
- CLLI: TOROON
- XJBG: TOR
- Tokyo 东京
- IATA: NRT, HND
- CLLI: TOKYJP
- XJBG: TOK, TYO
- Taipei 台北
- IATA: TPE
- CLLI: TAPITW
- XJBG: TAP, TAI
通常这些瞎鸡儿改的代码都是以方便阅读为宗旨而编写,然而,并没有什么标准(
常用位置代码列表
| City | IATA | CLLI | XJBG |
|---|---|---|---|
| Ashburn, VA | IAD | ASBNVA | ASH, WDC, DCA |
| Atlanta, GA | ATL | ATLNGA | |
| Chicago, IL | ORD, MDW | CHCGIL | CHI |
| Dallas, TX | DFW | DLLSTX | DAL |
| Houston, TX | IAH | HSTNTX | HOU |
| Los Angeles, CA | LAX | LSANCA | LA |
| Miami, FL | MIA | MIAMFL | |
| Newark, NJ | EWR | NWRKNJ | NEW, NWK |
| New York, NY | JFK, LGA | NYCMNY | NYC, NYM |
| San Jose, CA | SJC | SNJSCA | SJO, SF, SV |
| Palo Alto, CA | PAO | PLALCA | PA, PAIX |
| Seattle, WA | SEA | STTLWA | |
| Amsterdam, NL | AMS | AMSTNL | |
| Frankfurt, GE | FRA | FRNKGE | |
| Hong Kong, HK | HKG | NEWTHK | HGK |
| London, UK | LHR | LONDEN | LON, LDN |
| Madrid, SP | MAD | MDRDSP | |
| Montreal, CA | YUL | MTRLPQ | MTL |
| Paris, FR | CDG | PARSFR | PAR |
| Singapore, SG | SIN | SNGPSI | SGP, SNG |
| Seoul, KR | ICN, GMP | SEOLKO | SEL, SEO |
| Sydney, AU | SYD | SYDNAU | |
| Taipei, TW | TPE | TAIPTW | TAP, TAI |
| Tokyo, JP | HND, NRT | TOKYJP | TOK, TYO |
路由器接口种类
绝大多数的 ISP 都会把路由器的接口信息做成 PTR 记录的一部分,方便快速识别与排障。不过这些信息未必是最新的,因为很多大型网络会自动生成 PTR 记录。Be that as it may, 这也足够帮你去辨认这个路由节点是什么类型以及速率信息,再强一点的可甚至能猜到这个路由器的型号信息,举个例子:
上面这个是美国最大的网络运营商之一 Level3,我们可以用以下方式拆解这个 PTR 记录:
- NewYork1 代表这个路由节点在纽约,1 是机房编号。
- 这台路由是一台 Border Router。
- xe-#-#-# 是一个 Juniper 路由器的 10Gbps 接口,它最少有十二个 Slot。
- 这台路由器应该是最小 40Gbps / Slot 的,因为它的第一个 Slot 就已经是 10Gbps 的 PIC 了。
- 这台一定是 Juniper MX960,沒有其他的 Juniper 路由器符合这个规格了。
下面是一个常见的路由器接口类型的参考表:
| Interface Type | Cisco IOS | Cisco IOS XR | Juniper |
|---|---|---|---|
| Fast Ethernet (100Mbps) | fa#-# | fe-#-#-# | |
| Gigabit Ethernet (1Gbps) | gi#-# | gi#-#-#-# | ge-#-#-# |
| Ten Gigabit Ethernet (10Gbps) | te#-# | te#-#-#-# | xe-#-#-# |
| SONET / SDH | pos#-# | pos#-#-#-# | so-#-#-# |
| T1 (1.544Mbps) | se#-# | t1-#-#-# | |
| T3 (44.736Mbps) | t3-#-#-# | ||
| Ethernet Bundle (Link Aggregation) | po# / port-channel# | be#### | ae# |
| SONET Bundle (Link Aggregation) | posch# | bs#### | as# |
| IP Tunnel | tu# | tt# / ti# | ip-#-#-# / gr-#-#-# |
| ATM | atm#-# | at#-#-#-# | at-#-#-# |
| VLAN | vl | {interface type}#-#-#-#. | {interface type}-#-#-#. |
路由器类别与用途
有时候知道路由器的类别或者是用途也会方便我们了解这个节点。不过每一个网络都不同,用的路由器命名规则也不一样,甚至有时候 NOC 自己都不一定严格遵循命名方法。通常来说,我们可以通过猜测上下文来推测路由器的用途和类别:
- 核心路由 - cr, ccr, core, bb, gbr, ebr
- 边界路由 - br, bbr, border, edge, ir, igr, peer
- 客户路由 - ar, aggr, cust, car, hsa, gw
网络边界与关系
其实这个就很容易看出来了,而且通过了解网络边界的时候,我们可以得到一些很有用的信息,例如带宽不足或者延迟问题的源头来源可能是边界节点(实际上也确实是很容易出问题的地方),我们甚至可以看出一个 ISP 与另一个 ISP 之间的关系。ISP 互联之间的关系大致分为三种:
- IP Transit Provider(传输)
- Peer(互联)
- Customer(向客户提供传输网络)
通常 ISP 也会把互联关系写在 PTR 记录中,几个例子:
google.customer.alter.net(很明显了)digital.ocean.te0-0-0-13.br03.sin02.pccwbtn.net(这也是个客户关系)
通常路由器 PTR 记录发生改变的节点就是该网络的边界了:
1 | Loss% Drop Rcv Snt Last Best Avg Wrst StDev Gmean Jttr Javg Jmax Jint |
从这个结果中就可以看到,第 2、3 跳为 colocall 这家 ISP 的网络,第 4、5 跳为 Seabone 的网络,而从第 6 跳开始则进入了 NTT 的网络中,路由器的 ISP 名称都变了。所以,第 3、4、5、6 跳分别为 colocall、Seabone 和 NTT 的边界路由。
如果某个路由名称还包含了其他 ISP 的名称,那很有可能是这个 ISP 在路由所属 ISP 的客户路由。这也是边界路由的一种,如:
1 | 4 po2-20G.ar5.DCA3.gblx.net (67.16.133.90) |
从上面的例子中我们虽然可以分辨出边界路由(网络边界),不过我们并看不到一些更为详细的信息。这时候我们可以尝试看一下这个路由接口的另一面:
1 | Server: google-public-dns-a.google.com |
从另一边看,这个接口应该是一个 10G 的传输。所以从另一个角度看这个接口,可能会有更多的信息出现。
认识网络延迟
网络中,其实有三种事情会导致延迟的:
- 序列延迟(Serialization Delay)
分包而产生的延迟。 - 队列延迟(Queuing Delay)
路由器发包时需要排序并使用队列发送包,所以与路由的线路负载有关,因为如果没有阻塞,负载极低的情况下,队列延迟也几乎不存在。 - 传输延迟(Propagation Delay)
光、电等传输介质中的传导效率等问题导致的延迟。
序列延迟
这种延迟是由分包产生的。由于数据包在线路里只能逐个传送,所以我们只能等待第一个包传输完成后才能传输下一个包,这就造成了延迟。不过现在这类问题也越来越少见,随着时间推进,网速的提升,造成了数据包传输时间变短,延迟也越来越小。下面是几个不同的网络速度下传输一个数据包的时间(包为 1500bit):
| Speed | Time |
|---|---|
| 56Kbps | 212.4ms |
| T1(1.536Mbps) | 7.8ms |
| 100Mbps | 0.12ms |
| 1Gbps | 0.012ms |
排序延迟
首先,我们要知道一条线路的使用率到底是怎么一回事。如果我们有条 1Gbps 的线路,用去 500Mbps,直觉上这条线路的使用率是 50% 对吗?不过在现实中,一个接口的瞬时传输要么是 100% 传输,要么是 0% 传输的,换而言之,应该说这条线路在一秒内用掉了 50% 才对。
而排序,在路由器中是一个再正常不过的功能了。如果当有数据包进入路由器的接口,同时输出接口也在传输数据包时,路由器一定会等待输出结束之后才会继续传输输入的数据包。如果当一个路由器接口满载的时候,数据包会被延迟发送的概率也会大大增加。当一个路由接口完全满载的时候,数据包可能会被延迟数百甚至数千微秒才会被传出去。
传输延迟
这是由于传输距离造成的,也是最为主要的延迟原因之一(就是你感受到的延迟)。我们通常使用光来做长距离传输,光在真空中的速度为:$299,792,458 m/s$ (近乎 $300\times 10^{8}m/s$, 或 $300,000 km/s$)。而光纤的折射率大约为 1.48,所以光在光纤内的传播速率约为 $300,000\times \dfrac {1}{1.48}=\sim 200,000km/s$。而 $200.000km/s \sim 200km/ms$,举个例子,光绕地球来回跑一次大概就要 $400ms$ 了。
如何从 Traceroute 中辨认各种延迟因素
我们可以首先用路由名称的位置标记来估计位置,然后我们就可以从中猜测出的地点做地理位置距离的估算,从而估算延迟数据。再来个例子:
1 | 8 2 ms 2 ms 2 ms ae-3.r00.tkokhk01.hk.bb.gin.ntt.net [129.250.6.130] |
19ms 从香港去台北?香港到台北约为 812km,所以这个延迟其实还算合理。不过……
1 | 5 8 ms 8 ms 8 ms cr2.wswdc.ip.att.net (12.122.3.38) [MPLS: Label 17221 Exp 0] |
华盛顿到华盛顿要 220ms?不科学啊!
路由优先顺序与速率限制
要更加理解网络延迟,我们必须要理解现今路由器的基本架构。路由器传输数据包的部分我们称为 data plane。这部分是有路径传输的快慢之分的。
快速路径就是硬转发,无需路由器的处理器来做处理,速度很快,而绝大部分数据包都是用这种方式传输的。
慢传输路径则是需要对部分数据包做特殊处理时才会用到路由器的处理模块。我们发送的 traceroute 包与其他特别的包(如 IP Options 或其他 ICMP 包)都是会走这种路径的。
同时,也有一些包是直接传给路由器的,负责接收这部分包的部分我们称为 control plane。例如用于交换路由表的 BGP,用来管理路由器的 SNMP,Telnet 与 SSH 都是路由器的 control plane 负责。
由于路由器并不会常用到自己的处理器,所以他们的处理器的处理能力通常来说都不是很高。以一台可以满足 320Gbps~640Gbps 流量的路由器来说,他的 CPU 可能只有 600Mhz,而回应我们发送的 traceroute 包并不是路由器的主要考虑方面。
很多时候,data plane 的慢速路径会和路由器的 control plane 共用 CPU 资源,导致当 control plane 在使用过程中(如更新路由表,管理路由,监控等)会影响到 traceroute 的响应速度,从而导致了路由器发送 ICMP 包的 TTL Exceed 时间增加,会被误认为是网络问题。Cisco IOS 就有个 BGP Scanner 功能常常会导致这类随机的高延迟。
另外,大部分路由器会限制自身发送 ICMP 包的速度,以免路由器的 CPU 被 DDoS 攻击而影响(如 ICMP Flood 攻击等)。这些限制通常是固定的,在应付大量的 traceroute 请求时可能会高于这类限制,导致延迟看起来变高了。
最重要的是,如果网络真的出现了问题,在有问题的节点后的所有节点都应该受到这个节点的延迟影响。

上面的例子中,第四跳的路由节点延迟在 200ms 左右,之后的节点的延迟也受到影响,这就极有可能是网络问题。(其实没啥问题的,等下面讲 MPLS 的时候你就知道为什么了)
就算中间路由节点的延迟上升了,如果没有影响到随后的路由节点的延迟,也不算是网络问题。最差的情况则有可能是由于回程路由的问题导致的,不过通常是刚刚所说到的路由器限制。
非对称路由
非对称路由可以看作是 traceroute 的最大障碍。由于 traceroute 只能显示单方面的网络路由路径,所以你看到的每一跳的延迟值可能是由两部分组成:你到达该节点的时间与节点传输 ICMP TTL Exceed 包来回的时间。而且,除了 tracetroute 不能显示反向路由路径以外,回程路径是有可能和 traceroute 完全不同的。唯一的解决方案就是看双方的 traceroute 结果。不过,即便如此,也不一定能看出夹杂在中间的非对称路由路径。
非对称路由通常会出现在网络边界,因为网络边界路由通常是不同网络的交换点:
1 | te1-1.ar2.DCA3.gblx.net (69.31.31.209) 0.719 ms 0.560 ms 0.428 ms |
看过上面部分的朋友都应该知道这段路由其实是有问题的,不过问题到底出在哪里呢?有可能是 Global Crossing 与 Sprint 之间的拥塞,也可能是因为非对称的反向路由导致的。在 Global Crossing 与 Sprint 之间,路由策略发生了改变。这种情况通常发生在有多余上游 ISP 和互联的网络出现(因为有多种可用路由)。在上面的例子中,Sprint 的反向路由有个路由接口出现拥塞,但是并不能在上面的 trace 结果中看出来。
那么怎么才能通过 traceroute 知道反向路由有没有问题呢?答案是有的:通过控制 traceroute 的 src IP。然而这种办法并不是所有人都可以做到,所以暂且跳过。
非对称路由经常出现,尤其是当两个网络在多地都有链路的时候,路由器会优选,也就是选择距离自己最近的出口。
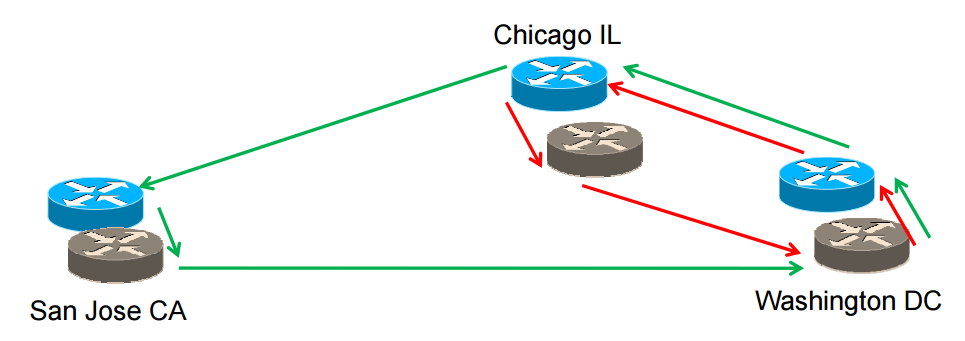
上图中,红色的路径就会通过芝加哥链路回去,而绿色的就会通过硅谷回去。
多重路由
因为 traceroute 可以使用 UDP 或者 TCP 来完成追踪过程,且端口号都不同,路由器的 ECMP(Equal Cost Multi-Path) 会把 traceroute 包做负载均衡,造成在 traceroute 上看到多重路由。这种现象倒没有什么问题,只是可能会导致 traceroute 结果比较混乱。几个例子:
1 | 1 TenGE0-1-2-0.cr04.hkg05.pccwbtn.net (63.218.174.58) 176 msec 172 msec |
上面这个例子中,三个 trace 有两个是走一条路由,剩下的一个走其他路由。
如果说上面这个你还能看懂,那下面这个就更复杂了:
1 |
|
看着很混乱吧?这就是因为路由器负载均衡的路由是不同长度而导致的。要想避免,可以设置 traceroute 每次只发送一个包,这样就看不到多重路由了。不过要记住,如果你真的这么做了,那出问题的地方不一定是你 trace 看到的那个路由,要尝试别的路由,办法是将 IP 位置 + 1 或者换个 src IP。
MPLS 与 Traceroute 的关系
现在有很多大型网络的核心路由都在用 MPLS,甚至有些路由连 BGP 表都么得,单纯靠包内的 MPLS Label 做发送。这对于发包来说没啥问题,但是要做 ICMP 响应就麻烦了。只支持 MPLS 的路由要怎么才能发出 IP 里的 ICMP 包呢?答案是使用 ICMP Tunneling,当 MPLS 路由需要发 ICMP 包时,路由会先把 ICMP 包塞到与 Traceroute 包同样的 Label-Switch Path 里,然后当这个 ICMP 包离开 Label-Switch Path 后,就会从末端的路由送回去。缺点是虽然可以正确发送信息,但是会让traceroute看着很奇怪。
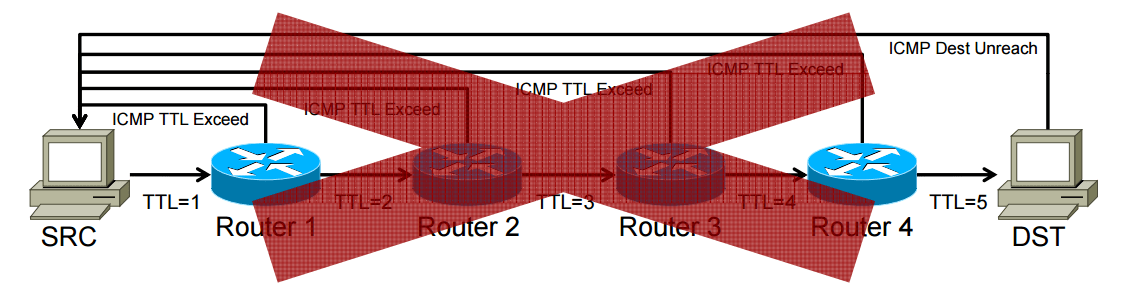
在有MPLS的情况下,traceroute就不会这么操作了。ICMP包要到Label-Switch Path的末端才能把ICMP Reply送回去(下图):
由于所有在Label-Switch Path里产生的ICMP响应都一定要到达MPLS末端才能折返,这就会令路由器的响应时间和目标的响应时间都差不多。几个例子:
1 | 1 bbs-1-250-0-210.on-nets.com (210.0.250.1) 1.055 ms 0.934 ms 0.890 ms |